Transparency & Methodology: To provide our research and M&A technical audits, we partner with marketplaces. If you click a link and make a purchase, we may earn a commission. We only recommend products, services, or assets that meet our technical standards. [ Learn more about our review process ]
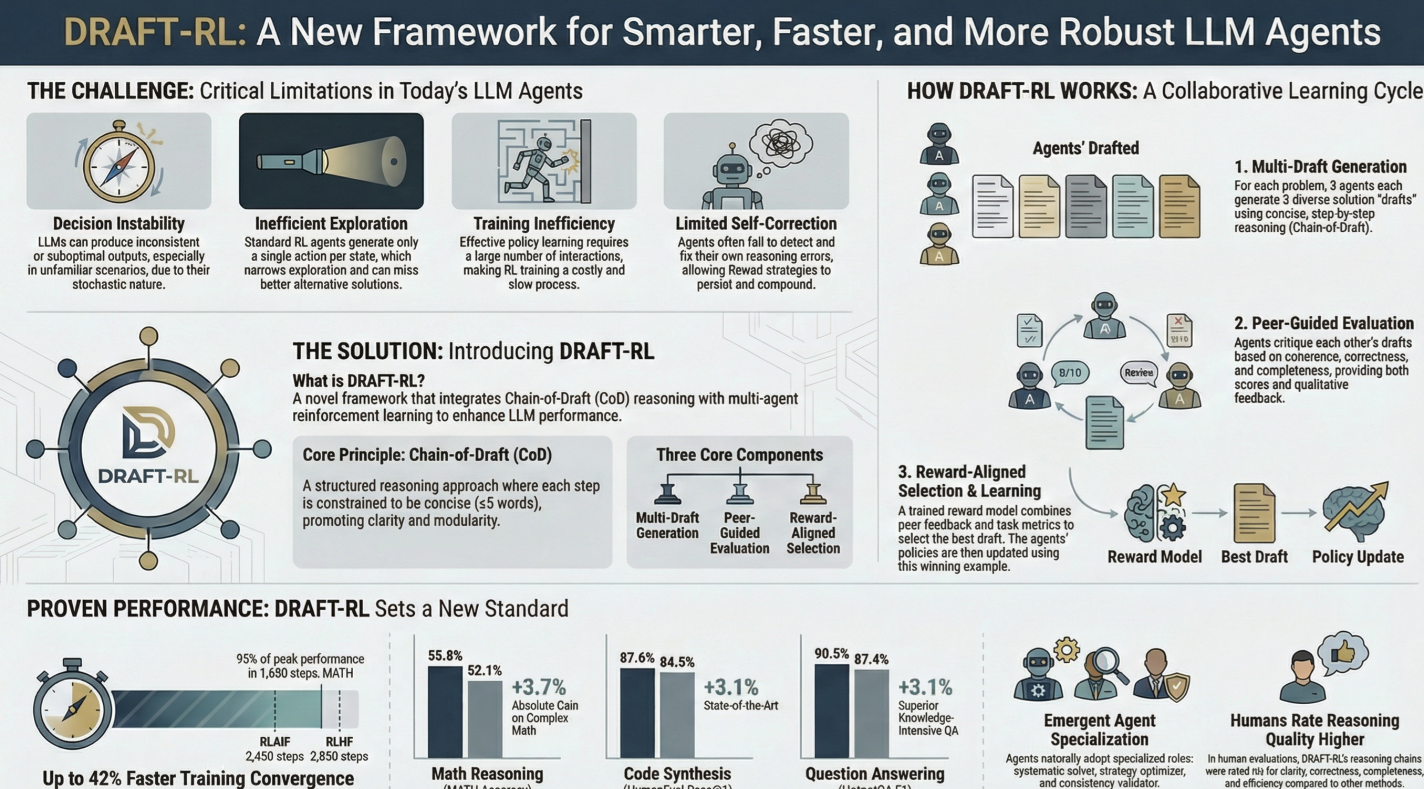
DRAFT-RL introduced a novel evaluation framework that integrates structured reasoning with multi-agent reinforcement machine learning. After the framework evaluation, the Large Language Models demonstrated remarkable capabilities in complex reasoning. The reasoning capabilities enabled the development of autonomous AI agents that can learn from experience through reinforcement learning (RL). However, current LLM-based RL AI agents face significant challenges that limit their effectiveness. Several challenges include decision instability under uncertainty and inefficient exploration due to single-path reasoning. Additionally, poor LLM training efficiency requires extensive interaction for LLM self-correction capabilities.
DRAFT-RL was designed to enhance the efficiency and interpretability of LLM agent behavior. The design enabled multiple agents to refine diverse solution pathways. Instead of generating a single response, each agent produces multiple concise reasoning rafts. Peer agents and a learned reward model assess these drafts. This process helps select the optimal trajectory for policy refinement.
Read More: Is This “Humanity’s Last Exam” For Language Models?
The primary contributions of the DRAFT-RL framework were:
To fully appreciate the innovations of DRAFT-RL, it is important to understand the research landscape from which it emerges. The framework reviewed key advancements in three interconnected domains: LLM-based agents, reinforcement machine learning with LLMs, and structured reasoning.
LLM-Based Agents and Multi-agent Systems
In the research, you can observe the development of single-agent frameworks. The development has enabled LLMs to generate complex action plans. The plans can also be executed with precision. Building on this, multi-agent systems introduced collaborative dynamics for evaluating.
After review, these systems demonstrated the value of collaboration. Yet they typically rely on a single-LLM response from each agent, lacking a structured mechanism for exploring diverse reasoning paths simultaneously. Above all, DRAFT-RL extends these collaborative principles by empowering each AI agent to generate multiple distinct drafts. These drafts are then subjected to a formal, peer-guided evaluation process. The framework leads to a comprehensive exploration of the solution space and parallelizes the search for viable reasoning paths.
Reinforcement Machine Learning with LLMs
As seen in the research, Reinforcement Machine Learning has become a central technique for aligning LLMs with human preferences. Some methods use preference data to train reward models. These methods include Reinforcement Learning from Human Feedback (RLHF). Another method is the more reliable Reinforcement Machine Learning from AI Feedback.
Related: What is Exoskeleton Reasoning For Language Models?
New machine learning techniques were successfully applied in domains such as code generation. Execution feedback was used to improve code quality. However, these methods traditionally train a single model to generate actions sequentially. DRAFT-RL contrasts with this single model approach by employing a multi-draft, multi-agent paradigm that facilitates more structured exploration.
Structured Reasoning In LLMs
Draft-RL structured reasoning techniques similar to exoskeleton reasoning have proven highly effective at improving LLM performance on complex tasks. As a result, Chain-of-Thought prompting encourages models to articulate intermediate reasoning steps. This laid the groundwork for this area. More recent extensions, such as Chain-of-Draft, refine this by constraining each reasoning step to be highly concise.
DRAFT-RL is the first framework to integrate CoD reasoning into a multi-agent reinforcement learning context. The framework leverages its structured, modular nature to guide exploration and improve the interpretability and Corrective metric of learned policies. While these foundational works establish the potential of collaborative and structured reasoning, they do not unify them within a learning framework.
Conclusion
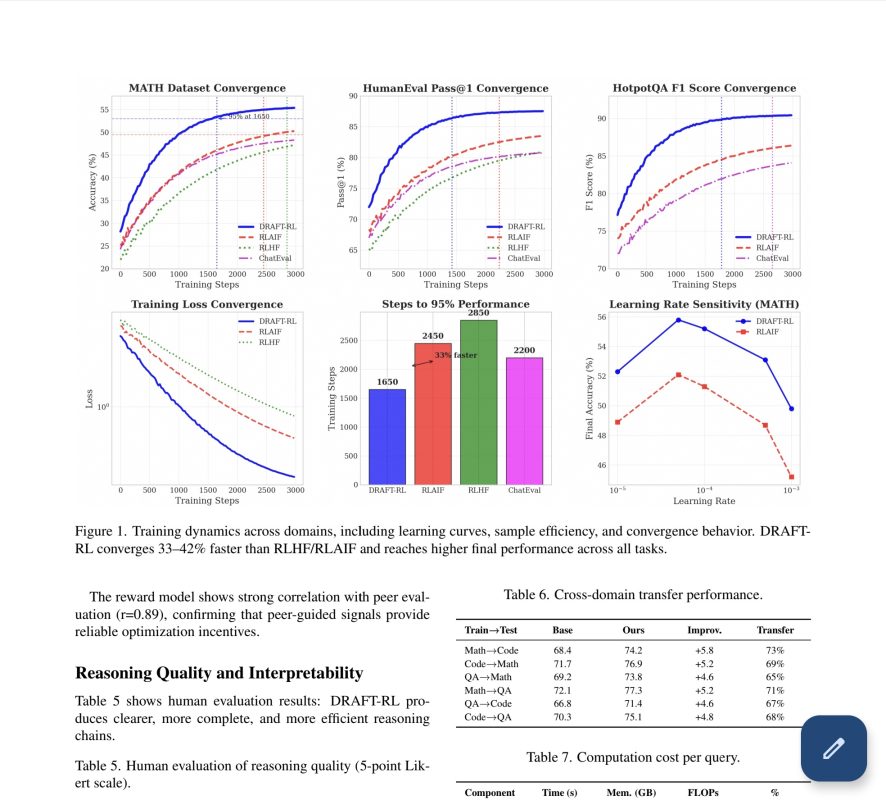
After reviewing the research report, it is evident that the DraftRL approach yields substantial performance Improvements, ranging from 2.4% to 4.5% over the strongest baselines, and a 3.7% absolute improvement in LLM performance on the challenging MATH dataset. Furthermore, the evaluation framework achieves these results while using 33–42% fewer training steps than strong RL baselines. These significant benefits result directly from the framework’s mechanisms.
References
Austin, J., Odena, A., Nye, M., Bosma, M., Michalewski, H., Dohan, D., Jiang, E., Cai, C., Terry, M., Le, Q., et al. Program synthesis with large language models. In arXiv preprint arXiv: 2021.
Yuan, X., Wang, X., Wang, C., Aggarwal, K., Tur, G., Hou, L., Deng, N., and Poon, H. Improving code generation by training with natural language feedback. arXiv preprint arXiv: 2023.
Disclosure: This Page may contain affiliate links. We may receive compensation if you click on these links and make a purchase.

