
Transparency & Methodology: To provide our research and M&A technical evaluations, we partner with marketplaces. If you click a link and inquire about an acquisition or make a purchase, we may earn a commission. We only recommend assets that meet our technical standards. [ Learn more about our review process.]
For modern businesses, proprietary data in the generative AI has moved beyond the hype cycle. It is now a rigorous race for LLM efficiency. As I covered in reports on LLM research, like the research paper titled “Artificial or Just Artful? Do LLMs Bend the Rules in Programming?” dive deep into how LLMs respond with proprietary data. Language models have reached unprecedented levels of sophistication, yet the local grounding of proprietary data limits their utility. As reported, to cross from experimental LLM pilots to enterprise-grade systems, organizations must anchor their AI strategy in proprietary data.
READ MORE: Google’s Antigravity Now Plugs Directly Into Your Enterprise Data
In this AI era, the model itself is a commodity. The primary differentiator is the unique, enterprise-proprietary data it leverages. The economic upside is substantial in evaluations. Enterprises leveraging proprietary data can achieve up to a 40% cost reduction compared to generic models. This amplifies their competitiveness in the race for efficiency.
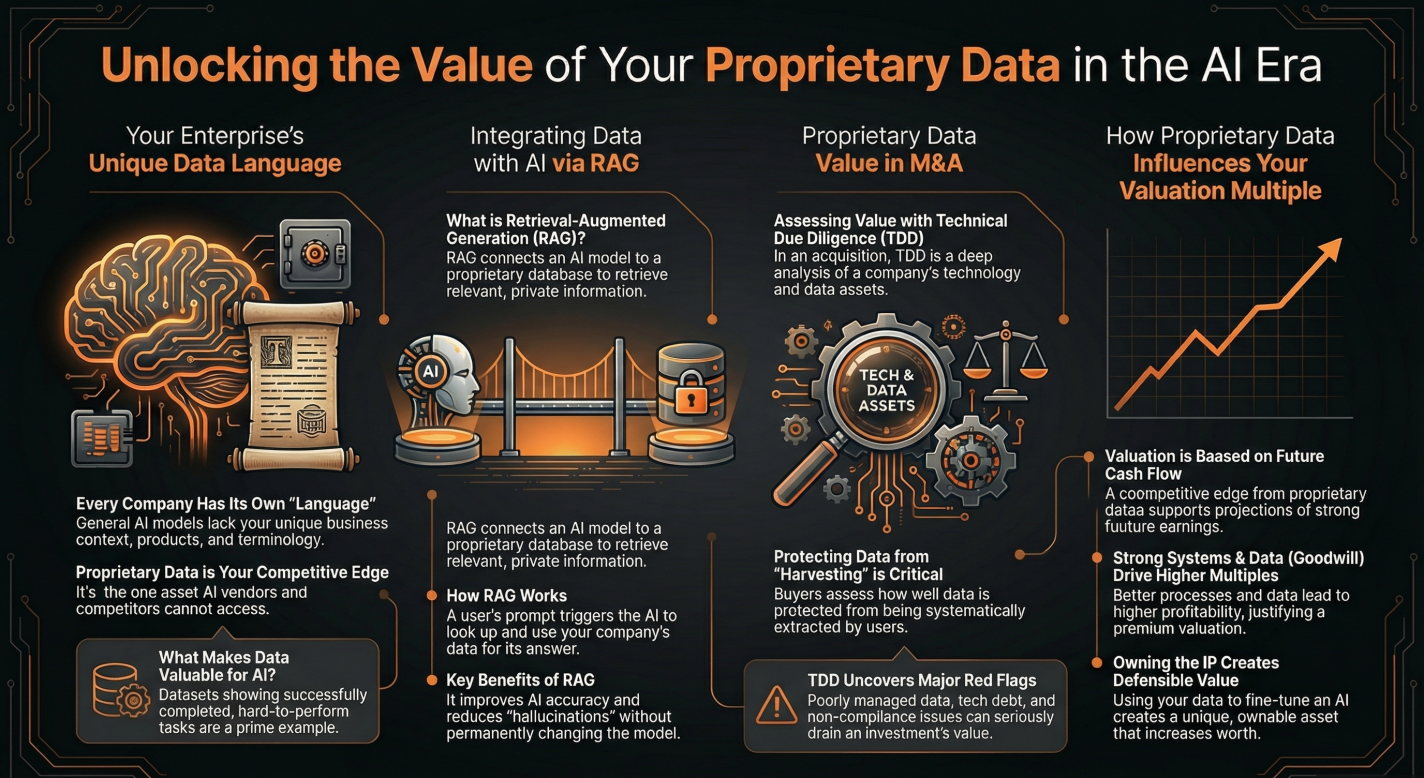
An Enterprise Proprietary Data Language
A recent report on LLMs, by Oussama Ben Sghaier, Kevin Delcourt, and Houari Sahraoui, shows that some language models stumble over the language of the enterprise. Off-the-shelf models and wrapper start-ups, trained on public data, lack these nuances. IBM research indicates that the top 15% of organizations are achieving quantifiable results. These organizations distinguish themselves by their confidence in customizing AI with proprietary data. Leaders in AI recognize that while any competitor can license a frontier model, no one can replicate proprietary data.
A business’s proprietary data may include the engineered prompts and fine-tuning data used to train LLMs. It may also include the company’s employee usage data. In a high-stakes valuation for an acquisition or merger, proprietary data dictates a business’s long-term asset value. Proprietary data that involves fine-tuning and modifying the layers of an AI or LLM network improves the cost-to-performance that is superior for high-frequency.
Proprietary Data Integrated With RAGRecon
Achieving proprietary data requires a deliberate architectural choice. This bridges the gap between public intelligence and private expertise. Retrieval-Augmented Generation (RAG) serves as a live bridge between a language model and an organization’s proprietary databases. It links a language model to a proprietary database to pull real-time, grounded facts. Using RAG provides a defense against language-model hallucinations on proprietary data.
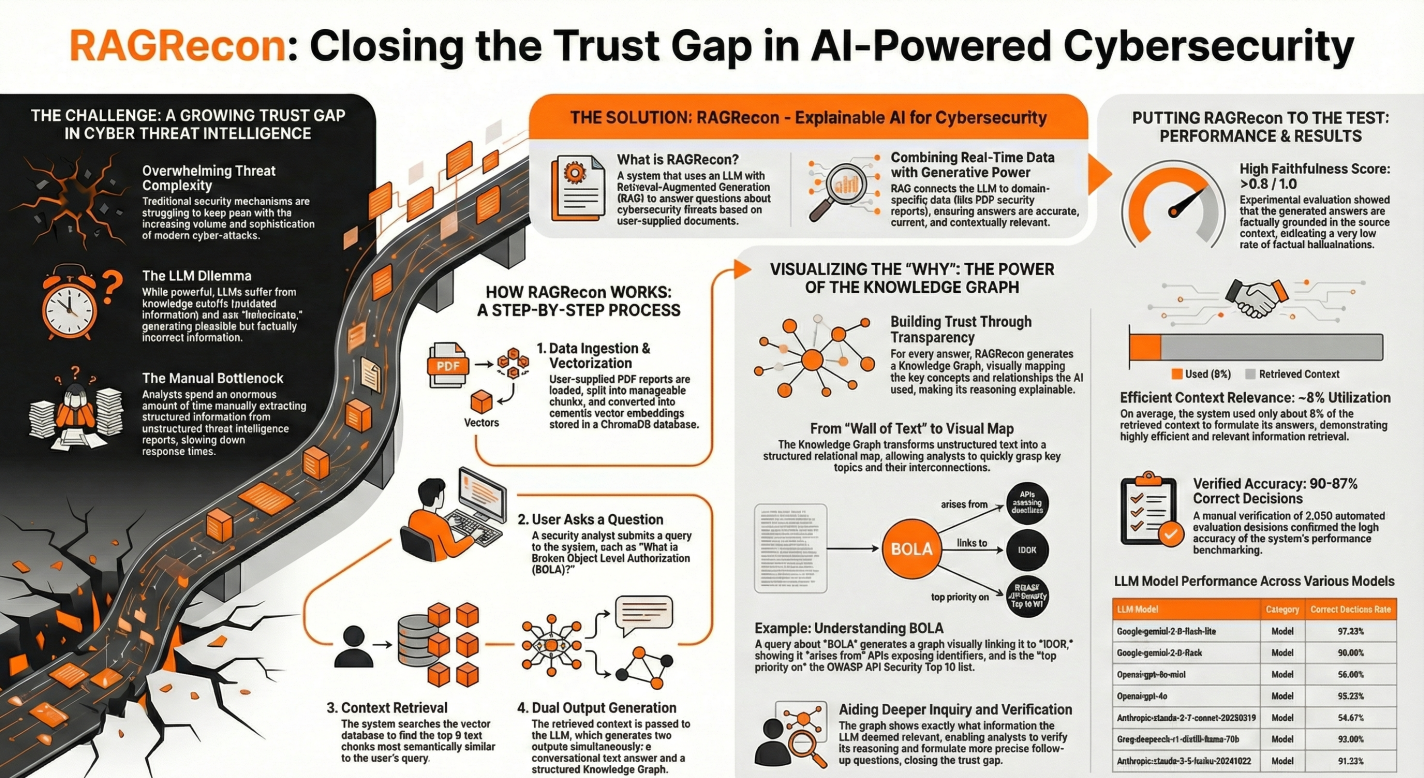
Proprietary data integrated with RAG helps large language models retrieve real-time information from connected data sources in response to queries. This significantly improves language model accuracy by grounding the model in factual, up-to-date documentation and proprietary data sources. According to recent LLM research, implementing RAG has been shown to reduce instances of language model hallucinations by up to 25%, improving AI performance.
Proprietary Data Value In M&A
In today’s landscape, proprietary datasets are the foundation of intangible assets in business valuation. To put technical definitions aside, when a buyer looks at your business, they arearen’tst buying historical tax returns. They are purchasing an opportunity to advance in AI. proprietary datasets bridge the gap between where the company has been and where it can go.
Proprietary datasets include established revenue streams and future growth targets, as well as LLM data and procedures that allow the business to function.. These are transferable assets that prove the company is a repeatable machine rather than a collection of random events.
How Proprietary Data Influences Your Valuation Multiple
In valuations, dissect your business through two primary lenses. High-value proprietary data that directly influences calculations by either de-risking future earnings or justifying a higher market position. If proprietary data on customer preferences, vendor relationships, and operational, how is locked in scattered data sources,? It is worthless without centralizing the data. In today’s market, investors will not finance a deal in which the seller’s proprietary assets are not with the company. As I’ve seen in prior acquisitions, businesses that have maximized the value of their proprietary data already had their data migrated to a platform designed for it.
To transition owned data to proprietary data, businesses can institutionalize process-driven knowledge. The procces knowledge can then be integrated into proprietary language models. We covered this in my reports on LLM research. As seen in recent mergers, a company’s proprietary data becomes significantly more valuable to an acquirer. Also, more useful when the intelligence data used to train the language model is owned by the enterprise. In business valuations, enterprise-owned data is what investors look for during technical evaluations. Therefore, a business’s proprietary data value lies in the type of data, automated AI pipelines, and it’s security measures.
Engineering Workflows Using Proprietary Data
The actual value of data is the data retrieval processes that are adapted to AI. As with most enterprises, they must move toward Agentic AI frameworks to blend data automation, and generative AI. A breakthrough moment is the transition and reimagining the customer support workflow. By integrating agentic AI agents, companies can automate responses and handle routine customer interactions more efficiently. With an AI-powered application, companies can expect to reduce customer query response time by 30%. Additionally, by reengineering generative AI processes, companies can automate mission-critical agentic AI agents to handle tasks end-to-end.
The businesses that are tailored for AI, GenAI is impossible without a modernized architecture that breaks down data silos. A hybrid cloud and secure data infrastructure ensures that proprietary data can be aggregated and fed into language models regardless of where it resides. Specifically, the hybrid architecture of the cloud addresses critical needs, including improving speed by enabling rapid data retrieval. It also ensures compliance through secure data management and optimizes costs by allocating resources more efficiently across cloud environments.
A business’s move to AI readiness also requires a data fabric that ensures interoperability and orchestrates fluid data movement. Optimized AI pipelines can deliver quantifiable results that directly impact a company’s bottom line. For instance, enterprise AI agent optimization is driven by prompt tuning and smart caching. This approach can achieve an average 90% reduction in latency. As a result, it improves user retention. It also reduces developer friction and accelerates product time-to-market.
Conclusion
The path to take advantage of your proprietary data, where large language models become the engine of modern business. The proprietary data is the fuel. The competitive moat is not found in a licensed model. It’s data context, hybrid infrastructure, and reengineered workflows. Organizations that successfully transition their data will build indefensible market positions by turning their proprietary data into an operational competency.
Disclosure: This Page may contain affiliate links, for which we may receive compensation if you click on these links and make a purchase.

