Technical Evaluation Report: DeepRails

DeepRails presents an opportunity to acquire its AI SaaS company with a defensive AI technology, that prevents AI hallucinations.
Technical Evaluation Report: DeepRails Read Article »
Enterprise-grade AI requires rigorous research backed LLM evaluation and guardrails safety frameworks. Block Article explores the automated testing methodologies designed to ensure model reliability. We analyze technical frameworks used to monitor AI behavior and the research-backed guardrails that prevent hallucinations and protect enterprise applications from adversarial exploits
DeepRails presents an opportunity to acquire its AI SaaS company with a defensive AI technology, that prevents AI hallucinations.
Technical Evaluation Report: DeepRails Read Article »
A GenAI LLM evaluation engine and integrated API platform presents a opportunity to aquire its assets.
The Kill-Switch For AI Hallucinations Enters The M&A Market Read Article »

AI LLM software is appealing due to its efficiency. However, their true value is in identifying entirely new avenues for generating income and improving customer experiences.
Discover how AI LLM Software Improves Profits and Customer Experiences for Businesses Read Article »

Acquiring an LLM presents an investment that can offer a compelling path to substantial return on investment and business growth.
Top Five Reasons Why Acquiring an AI LLM Can Grow Your Business With an ROI Read Article »

Companies, from local storefronts to global enterprises, are acquiring large language models. Why? these models offer a unique competitive edge through implementation.
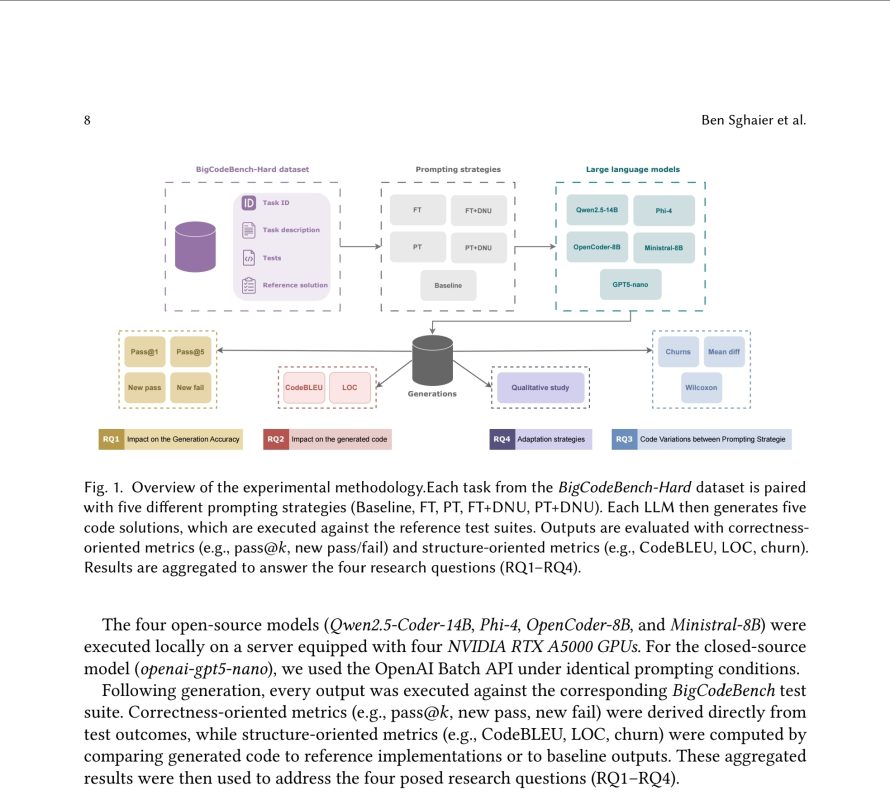
An LLM research paper, titled “Artificial or Just Artful? explores the tension between pretraining objectives and alignment constraints in Large Language Models (LLMs). The researchers specifically investigated how models adapt their strategies when exposed to test cases from the BigCodeBench (Hard) dataset.
Do LLMs Bend the Rules in Programming When They Have Access to Test Cases? Read Article »
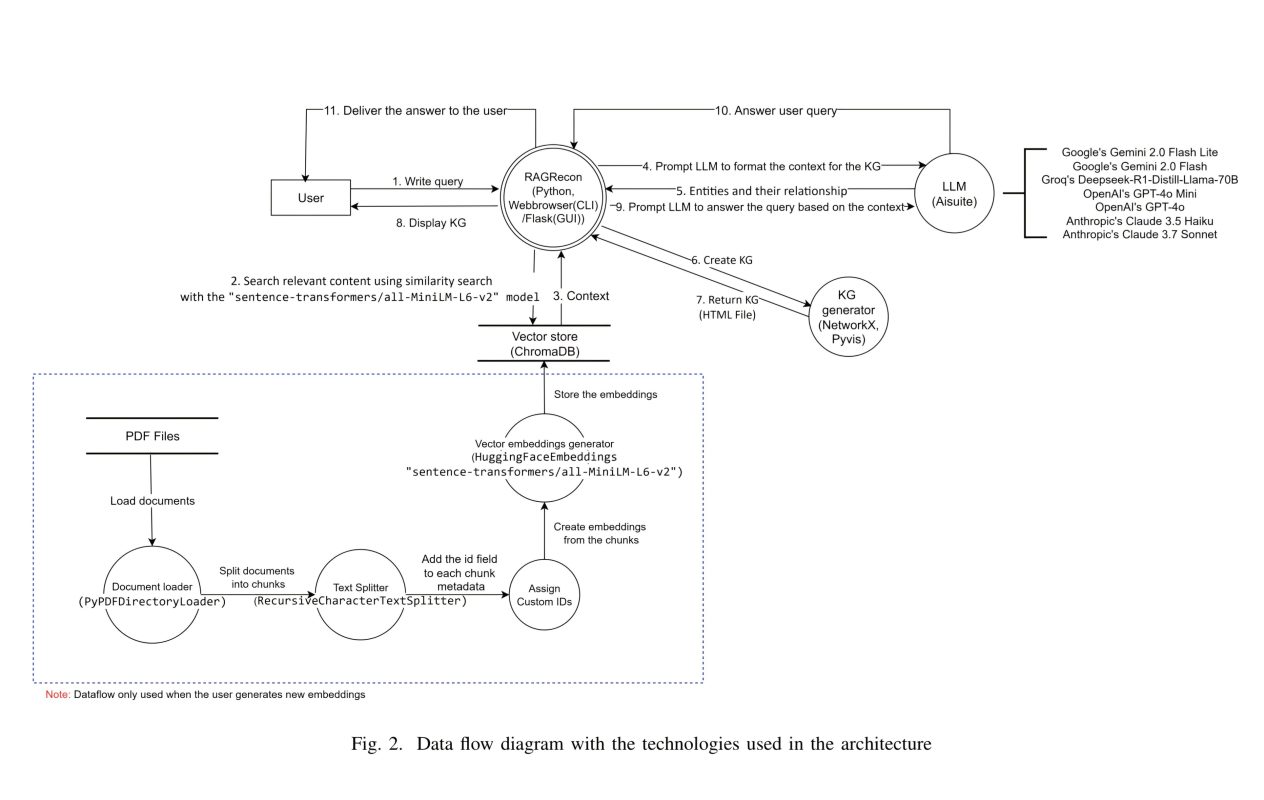
RAGRecon, a system to improve Cyber Threat Intelligence through the integration of Large Language Models and Retrieval-Augmented Generation.
Is Your AI Target Defensible? How RAGRecon Solves the Trust Gap in Cybersecurity Read Article »
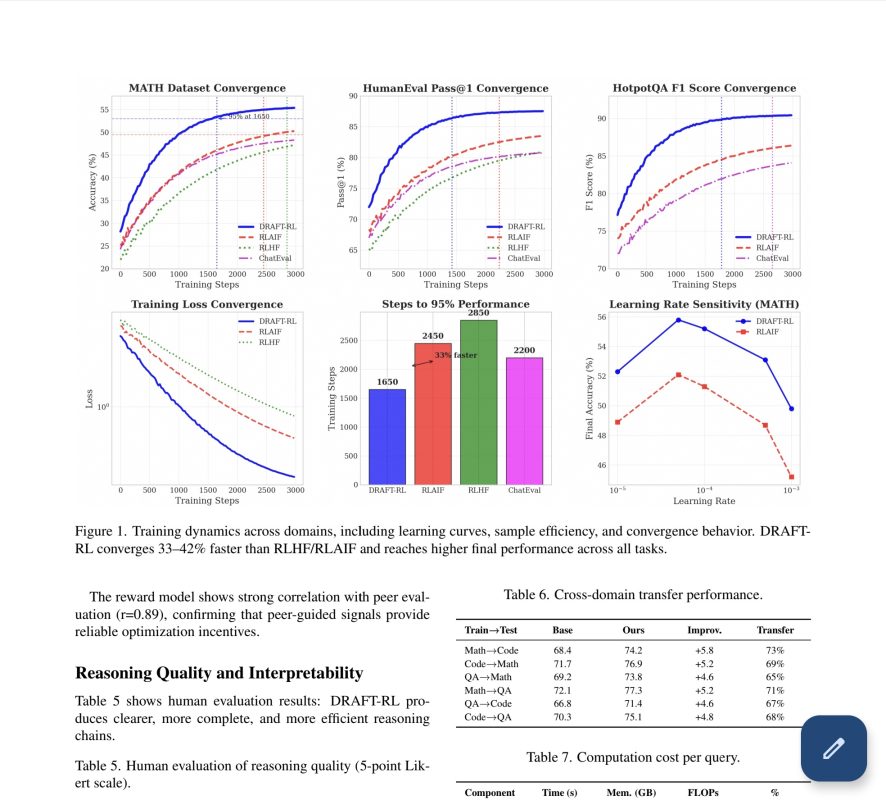
DRAFT-RL is a evaluation framework fort LLMs designed to address critical limitations in LLM-based reasoning systems by integrating Chain-of-Draft (CoD) reasoning with multi-agent reinforcement learning.

The Language Model Council research suggests that the top spot on any given leaderboard might be an artifact of evaluation design rather than a reflection of superior, generalized capability.
How Did 20 LLMs Dethroned GPT-4o and Reveal the Flaws in AI Leaderboards Read Article »

Humanity’s Last Exam is a multi-modal case study designed to measure the capabilities of large language models.
Is This Humanity’s Last Exam… For Language Models? Read Article »

Exoskeleton Reasoning is a process that inserts a directed validation scaffold into A language model’s workflow before it responds.
What is Exoskeleton Reasoning For Language Models? Read Article »

A new research paper from Humains-Junior language model reportedly matches the factual accuracy of GPT-4o on a specific public subset. According to the paper the Humains-Junior language model achieves this performance through an innovative method called “Exoskeleton Reasoning.”
Humains-Junior Language Model Challenges GPT-4o on Factual Accuracy Read Article »

A Small Language Model can be as Accurate as a Large Language Model with evaluation methods and frameworks. Methods like Exoskeleton Reasoning, Completeness, and Correctness, and using an LLM as a judge.
Can A Small Language Model Be As Accurate As a Large Language Model? Read Article »