
Are we really looking at Humanity’s Last Exam for language models? LLMs and AI have advanced, now exceeding LLM performance across a diverse range of tasks in many fields. However, state-of-the-art LLMs are now exceeding these popular benchmarks, achieving over 90% accuracy. Accurately measuring current AI LLM capabilities requires creating more challenging LLM evaluations to track the rapid improvements in LLM technology. The case study, Humanity’s Last Exam, provides several interesting discoveries regarding the current state and limitations of state-of-the-art Large Language Models when tested on cutting-edge technology.
Humanity’s Last Exam Case Study
My First review of Humanity’s Last Exam revealed a significant performance gap in LLMs capabilities and reasoning. Even the most advanced models achieve remarkably low accuracy. This results in the case study displaying a need for a more rigorous evaluation tool. An LLM evaluation that’s capable of precisely measuring capabilities at the upper echelons of machine knowledge.
Related: The “kill-switch for AI hallucinations” in LLM Evaluation Enters The M&A Market
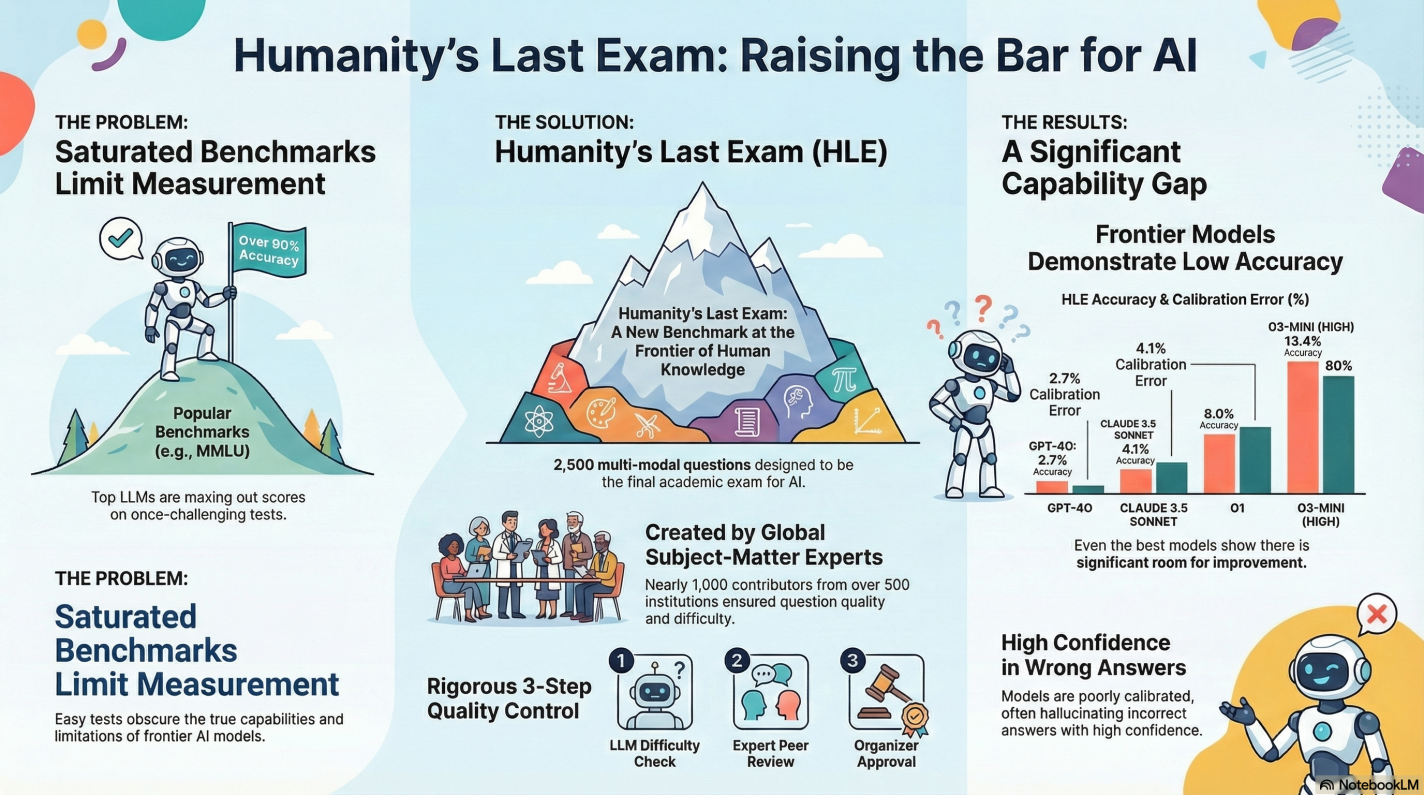
The Humanity’s Last Exam consisted of 2,500 publicly released questions. A private test set was held to prevent language models from overfitting the evaluation. In terms of format, the evaluation benchmark leaned heavily toward exact-match (short-answer) questions, at 76%. While the remaining 24% are multiple-choice (which required selecting one of five or more options). Notably, approximately 14% of the questions are multi-modal, necessitating the comprehension of both text and an image reference.
The creation of HLE was a vast global collaborative effort, recruiting nearly 1,000 subject expert contributors. The contributors included primarily professors, researchers, and graduate degree holders, who are affiliated with over 500 institutions across 50 countries. To make the test competitive, a $500,000 prize pool was offered alongside the opportunity for paper co-authorship. The subjects covered span over a hundred domains, organized into key primary categories. Subjects included Math, Humanities/Social Science, Biology/Medicine, Computer Science/AI, and Physics, with a specific emphasis on testing deep mathematical reasoning skills.
Humanity’s Last Exam Design Principle
The core design principle is powerful in creating questions that test deep reasoning, not just information retrieval. Each question has a known and easily verifiable solution, but cannot be quickly answered via internet retrieval. The filtering process was fascinating to say the least, as every potential question was tested against frontier LLMs. To find just 13,000 candidate questions for human review, the team logged over 70,000 attempts against these top AIs. The questions that successfully stumped the AIs then underwent a rigorous two-stage human review process, in which graduate-level experts refined them.
Final Thoughts
The Humanity’s Last Exam might be the last academic exam we need for AI. However, it is far from the last evaluation benchmark. The AI/ML field is moving very fast, and the authors predict that models could plausibly exceed 90% accuracy on tough tests by the end of 2025. SO, Humanity’s Last Exam provides a much-needed, clearer picture of where the world’s most advanced AI models truly stand today. The HLE Study shows it’s not just what LLM can know and do, but how a language model can fail. Does this LLM evaluation give us a new way to measure AI progress against? Because once AI masters the exam, how will we measure the AI that comes next?
Disclosure: This Page may contain affiliate links, for which we may receive compensation if you click on these links and make a purchase. However, this does not impact our content.
Reference
Long Phan, Alice Gatti, Ziwen Han, Nathaniel Li, et al. (Total 1109 authors). Humanity’s Last Exam (v9). arXiv:2501.14249 [cs.LG], 25 Sep 2025. URL: https://arxiv.org/abs/2501.14249.

